Collaborative metric learning
Hsieh, C.-K., Yang, L., Cui, Y., Lin, T.-Y., Belongie, S. and Estrin, D.
In Proceedings of the 26th international conference on world wide web, 2017, pp. 193-201
[BibTeX]
@inproceedings{Hsieh2017,
author = {Hsieh, Cheng-Kang and Yang, Longqi and Cui, Yin and Lin, Tsung-Yi and Belongie, Serge and Estrin, Deborah},
title = {Collaborative metric learning},
booktitle = {Proceedings of the 26th international conference on world wide web},
year = {2017},
pages = {193--201}
}
Image-based recommendations on styles and substitutes
McAuley, J., Targett, C., Shi, Q. and Van Den Hengel, A.
In Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval, 2015, pp. 43-52
[BibTeX]
@inproceedings{McAuley2015,
author = {McAuley, Julian and Targett, Christopher and Shi, Qinfeng and Van Den Hengel, Anton},
title = {Image-based recommendations on styles and substitutes},
booktitle = {Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval},
year = {2015},
pages = {43--52}
}
Image-based recommendations on styles and substitutes
McAuley, J., Targett, C., Shi, Q. and Van Den Hengel, A.
In Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval, 2015, pp. 43-52
[BibTeX]
@inproceedings{McAuley2015a,
author = {McAuley, Julian and Targett, Christopher and Shi, Qinfeng and Van Den Hengel, Anton},
title = {Image-based recommendations on styles and substitutes},
booktitle = {Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval},
year = {2015},
pages = {43--52}
}
Navigation Graph for Tiled Media Streaming
Park, J. and Nahrstedt, K.
Association for Computing MachineryIn Proceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 447–455
[BibTeX] [DOI]
@inproceedings{Park2019,
author = {Park, Jounsup and Nahrstedt, Klara},
title = {Navigation Graph for Tiled Media Streaming},
booktitle = {Proceedings of the 27th ACM International Conference on Multimedia},
publisher = {Association for Computing Machinery},
year = {2019},
pages = {447–455},
url = {https://doi.org/10.1145/3343031.3351021},
doi = {https://doi.org/10.1145/3343031.3351021}
}
GRADES: Gradient Descent for Similarity Caching
Sabnis, A., Si Salem, T., Neglia, G., Garetto, M., Leonardi, E. and Sitaraman, R.K.
In IEEE INFOCOM 2021 - IEEE Conference on Computer Communications (INFOCOM 2021), May, 2021
[BibTeX]
@inproceedings{Sabnis2021,
author = {Anirudh Sabnis and Tareq Si Salem and Giovanni Neglia and Michele Garetto and Emilio Leonardi and Ramesh K Sitaraman},
title = {GRADES: Gradient Descent for Similarity Caching},
booktitle = {IEEE INFOCOM 2021 - IEEE Conference on Computer Communications (INFOCOM 2021)},
year = {2021}
}
RecVAE: A New Variational Autoencoder for Top-N Recommendations with Implicit Feedback
Shenbin, I., Alekseev, A., Tutubalina, E., Malykh, V. and Nikolenko, S.I.
In Proceedings of the 13th International Conference on Web Search and Data Mining, 2020, pp. 528-536
[BibTeX]
@inproceedings{Shenbin2020,
author = {Shenbin, Ilya and Alekseev, Anton and Tutubalina, Elena and Malykh, Valentin and Nikolenko, Sergey I},
title = {RecVAE: A New Variational Autoencoder for Top-N Recommendations with Implicit Feedback},
booktitle = {Proceedings of the 13th International Conference on Web Search and Data Mining},
year = {2020},
pages = {528--536}
}
Collaborative deep learning for recommender systems
Wang, H., Wang, N. and Yeung, D.-Y.
In Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining, 2015, pp. 1235-1244
[BibTeX]
@inproceedings{Wang2015,
author = {Wang, Hao and Wang, Naiyan and Yeung, Dit-Yan},
title = {Collaborative deep learning for recommender systems},
booktitle = {Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining},
year = {2015},
pages = {1235--1244}
}
Similarity Caching Trace Repository
This page contains traces for similarity caching evaluation.
Downloads and summary
Maintainers: Tareq Si Salem and Giovanni Neglia.
| Trace | Number of requests | Catalog size | Dimension (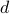 ) ) | Download link |
| Amazon trace | 908,179 | 63,891 | 100 | Requests Embeddings |
| CiteULike trace | 2,411,819 | 153,277 | 100 | Requests Embeddings |
| Movielens trace | 620,222 | 136,677 | 200 | Requests with embeddings |
| 360° videos trace | 10,000,000 | 25,393 | 3 | Tiles requests |
If you are going to use any of these traces, we invite you to cite the appropriate references listed below:
Amazon trace: McAuley et al. (2015) and Sabnis et al. (2021).
CiteULike trace: Wang et al. (2015), Hsieh et al. (2017) and Sabnis et al. (2021).
Movielens trace: Shenbin et al. (2020) and Sabnis et al. (2021).
360° videos trace: Park and Nahrstedt (2019) and Sabnis et al. (2021).
Data format
The traces are pickled pandas DataFrames with gzip compression. To load a dataset use the following code snippet:
import pandas as pd requests = pd.read_pickle('amazon_request_process.pkl', compression = 'gzip') embeddings = pd.read_pickle('amazon_embeddings.pkl', compression = 'gzip')
Amazon trace
Contributors: Giovanni Neglia and Tareq Si Salem.
The authors McAuley et al. (2015) collected a data-set from crawling the amazon web-store to model the relationships between items, and learn how to provide recommendations to users. They take as input feature vectors of size , obtained from the output of a neural network, pre-trained on 1.2 million ImageNet images, and they also include the relationships between the items, these relationships are collected based on the cosine similarity of the sets of users who purchased or viewed the items, and they model objects similarity as a distance
, obtained from the output of a neural network, pre-trained on 1.2 million ImageNet images, and they also include the relationships between the items, these relationships are collected based on the cosine similarity of the sets of users who purchased or viewed the items, and they model objects similarity as a distance 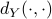 , such that P(item
, such that P(item 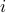 is related to item
is related to item 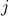 ) increases monotonically with
) increases monotonically with 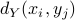 , where
, where 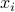 and
and 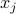 are the visual features of the items and of size
are the visual features of the items and of size 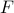 . In this process, they learn a d-dimensional embedding
. In this process, they learn a d-dimensional embedding 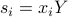 , where
, where 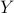 is a matrix of dimension
is a matrix of dimension 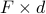 , the similarity distance is given as
, the similarity distance is given as 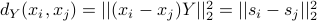 , and the items now live in d-dimensional “style-space”. Sabnis et al. (2021) considered the request process as the timestamped reviews left by users, this gives a sequence of requests to items embedded in a d-dimensional space, where the Euclidean distance between items represents their similarity. The relation “users who viewed also viewed ” is considered and has the highest accuracy (96.6%) in the category Baby for
, and the items now live in d-dimensional “style-space”. Sabnis et al. (2021) considered the request process as the timestamped reviews left by users, this gives a sequence of requests to items embedded in a d-dimensional space, where the Euclidean distance between items represents their similarity. The relation “users who viewed also viewed ” is considered and has the highest accuracy (96.6%) in the category Baby for 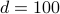 .
.
CiteULike trace
Contributors: Giovanni Neglia, Tareq Si Salem and Caelin Kaplan.
The embeddings are obtained using the Collaborative Metric Learning (CML) model proposed in Hsieh et al. (2017): This model learns an embedding of both users and items in d = 100 dimensional space, and the Euclidean distance within this space encodes the similarity between users and items. The dataset CiteULike Wang et al. (2015) is a bipartite network of 22,715 users and 153,277 tags, where each edge represents a timestamped creation of a tag. Sabnis et al. (2021) used the same embedding dimension and loss function used in Wang et al. (2015), and they were unable to reproduce the same performance. The embeddings for the CiteULike dataset resulted in a recall@50 of 29.9%, compared to 33.65%. The trace considered by Sabnis et al. (2021) is the sequence of tag creations with the associated tag embeddings.Movielens trace
Contributors: Giovanni Neglia, Tareq Si Salem and Abdelkarim Hafid.
Sabnis et al. (2021) train the RecVAE model in Shenbin et al. (2020) used for collaborative filtering. The model has an encoder-decoder architecture, where the encoder learns implicitly embeddings of users’ ratings in a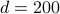 dimensional space, users having similar rating history are mapped next to each other, so that the decoder can provide a similar prediction. Sabnis et al. (2021) used MovieLens-20M dataset to train the model, 50% of the users have more than 38 ratings in the test dataset of the model, and they considered this value as the threshold to obtain a new embedding for a user. Then an embedding is obtained every batch of 38 ratings, and this embedding is timestamped by the latest timestamp in the batch of ratings.
dimensional space, users having similar rating history are mapped next to each other, so that the decoder can provide a similar prediction. Sabnis et al. (2021) used MovieLens-20M dataset to train the model, 50% of the users have more than 38 ratings in the test dataset of the model, and they considered this value as the threshold to obtain a new embedding for a user. Then an embedding is obtained every batch of 38 ratings, and this embedding is timestamped by the latest timestamp in the batch of ratings.
360° videos trace
Contributors: Giovanni Neglia and Anirudh Sabnis.
Sabnis et al. (2021) generated a sequence of tiles’ requests for 360° videos using the approach proposed in Park and Nahrstedt (2019). They took real traces from 8 videos watched by 48 users each, and then built a navigation graph for each video, i.e., a Markov Chain that represents the spatial and temporal viewing correlations for the video. The videos considered have on average 207 segments, each with 25 tiles. From each navigation graph an arbitrary number of possible views of the video is generated. A trace with 10000 users is generated as follows. At time t = 0, each user selects one of the videos at random and starts watching the video from a random segment of the video. The user then walks through the navigation graph to view the complete video. Once the user reaches the last segment in the video, it selects a new video uniformly at random (with replacement) and starts watching the selected video from the first segment. The process is repeated till 10 million requests are generated.